文本提取器可帮助您将扫描的PDF文档,数字图像转换为可搜索和可编辑的文本内容。它可以通过先进的OCR(光学字符识别)技术消除您的重新输入工作,该技术可以准确地识别图像中的文本并有效地提取文本内容。
主要特点:
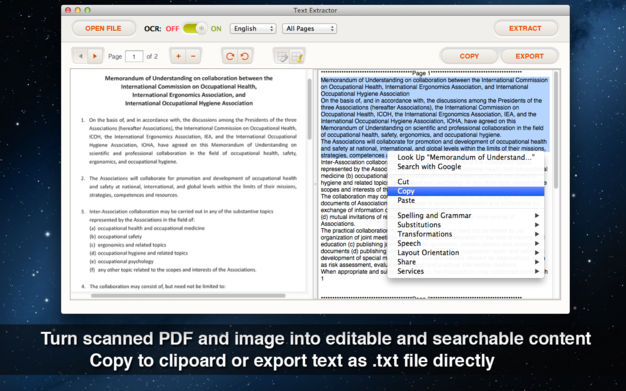
*将PDF和图像转换为可搜索和可编辑的文本内容
如果你有一个扫描的PDF或图像文件,你会感到很沮丧,如果你想获得信息,你必须手动重新输入它们。使用文本提取器,您可以解锁文本内容,轻松获取和使用PDF文件中锁定的信息。
*高级OCR功能
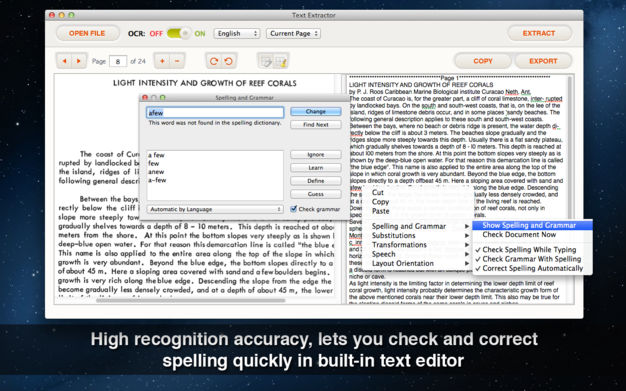
当您扫描纸质文档并将其另存为PDF或图像文件时,实际上整个内容将被捕获为图像而不是文本和字体信息,OCR技术用于文本识别。准确性是OCR应用程序的核心,如果源文件具有高质量,Text Extract的识别准确率可高达90%。节省您转换后纠正错误的时间。
*直观的界面,易于使用
OCR转换不是一件容易的事,但通过易于使用的界面,您可以用更少的步骤完成提取。
1.打开PDF或图像文件,
2.选择文档语言,
3.单击“提取”按钮开始OCR识别,
4.完成后,您可以将文本复制到剪贴板或将其导出为.txt文件。
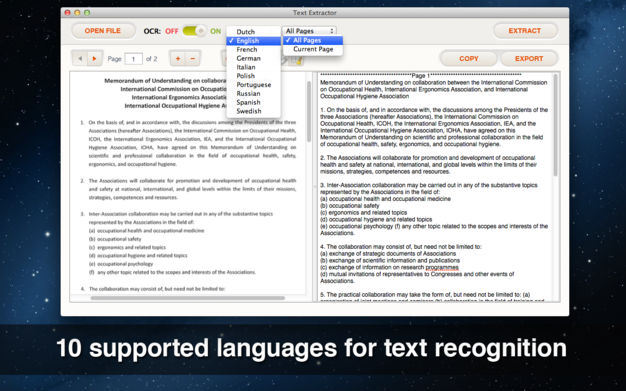
*广泛的支持语言
文本提取可以检测10种语言,包括英语,法语,德语,意大利语,瑞典语,俄语,波兰语,荷兰语,西班牙语,葡萄牙语。
*以更高的速度进行高效转换
Text Extractor可以有效地将大型PDF文档和图像转换为可编辑和可搜索的文本,并更快地传送转换后的文本内容。如果未启用OCR,则提取每个页面所需的时间不到1秒。
它允许您直接在内置文本编辑器中编辑和修改提取的文本内容,您可以将内容复制到剪贴板并导出为纯文本(.txt)。
*您可以采取以下措施来改善OCR结果:
– 对于标准打印文本,请将分辨率提高到300 dpi,对于小字体,请将分辨率提高到更高,
– 在执行OCR之前将页面旋转到正确的方向。
– 选择正确的文档语言,
– 选择您不想提取的区域可以提高转换准确性和效率,例如图像和图表等。
